Decision Tree Classification Algorithm Presentation
| Introduction to Decision Tree Classification Algorithm | ||
|---|---|---|
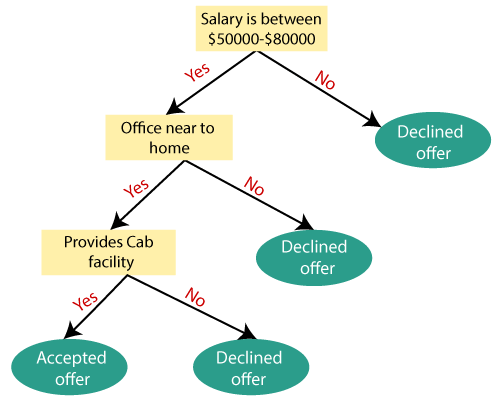
| Decision tree classification is a popular and widely used algorithm in machine learning. It is a supervised learning method used for both classification and regression tasks. It builds a tree-like model of decisions and their possible consequences. | ||
| 1 | ||
| How Decision Trees Work | ||
|---|---|---|
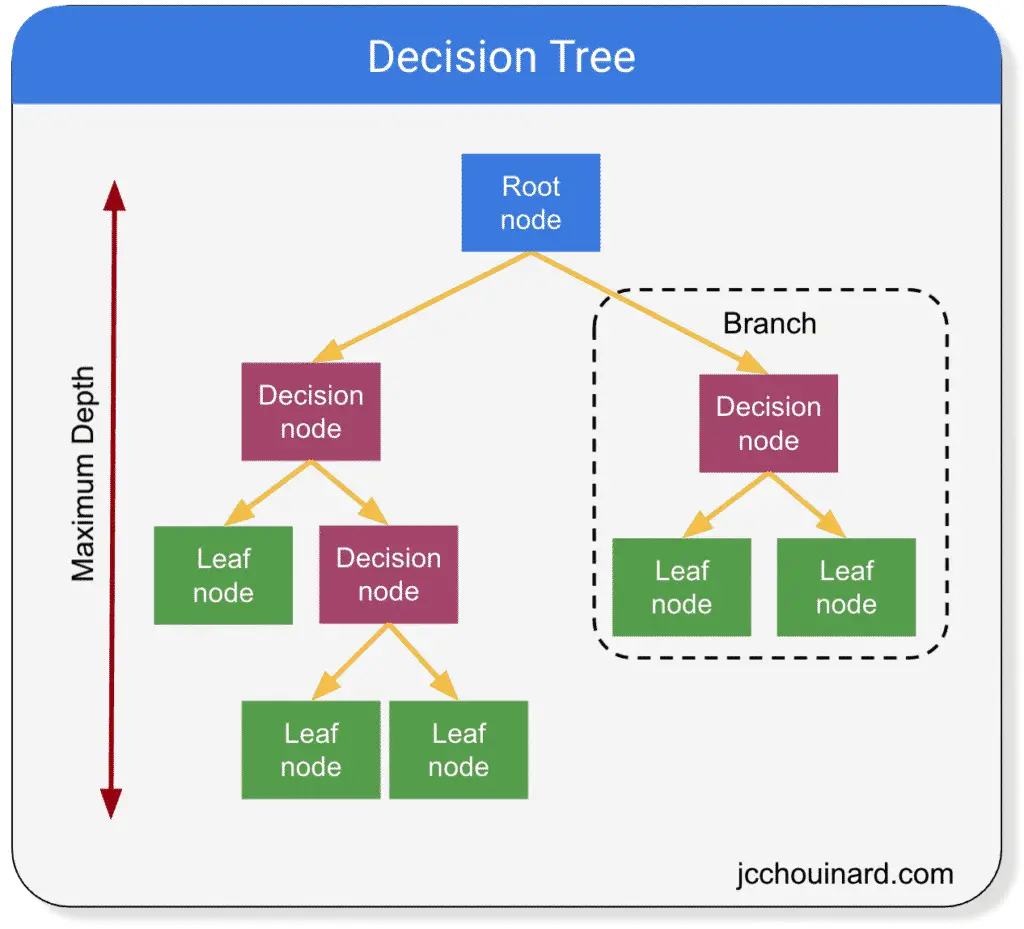
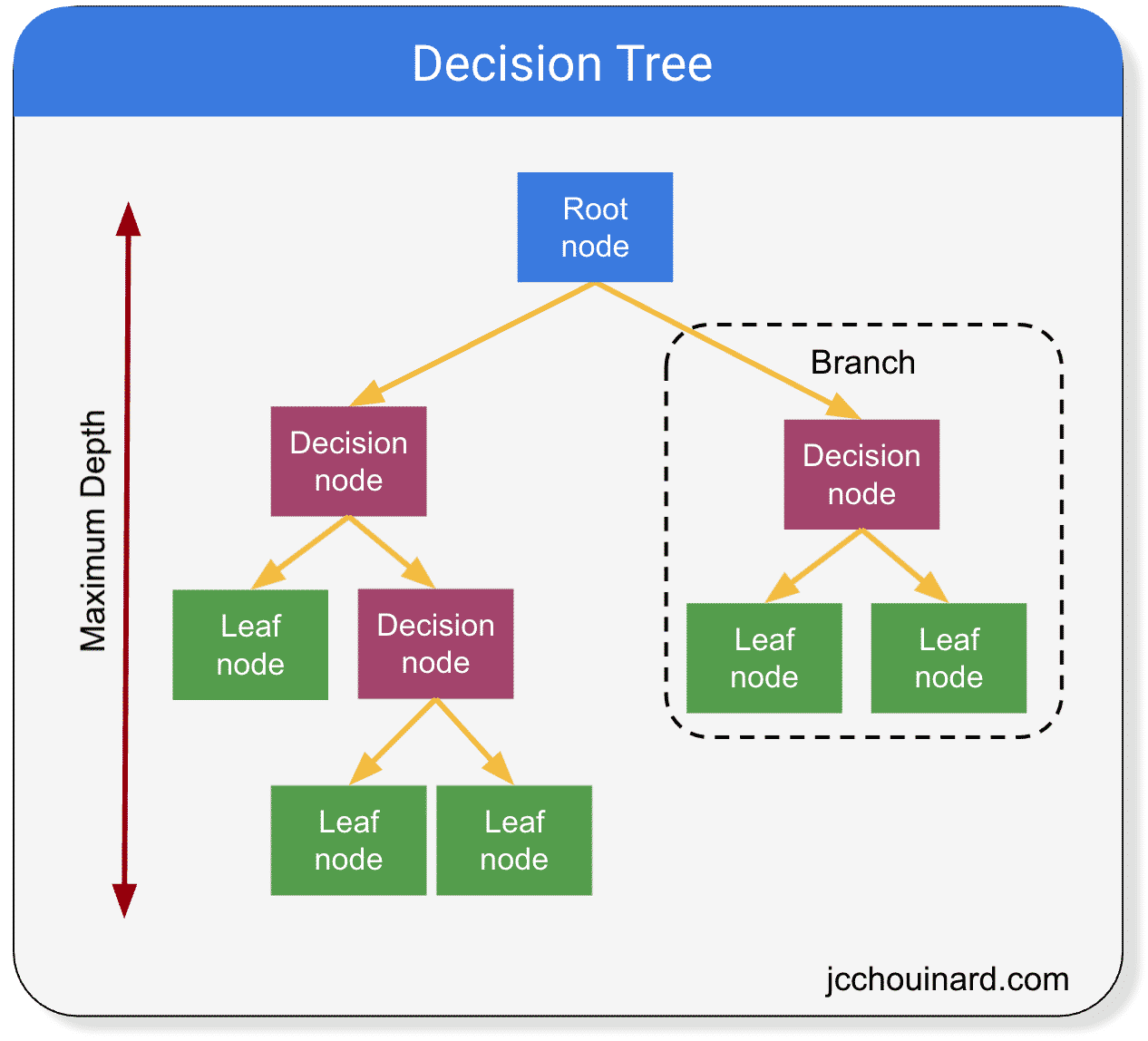
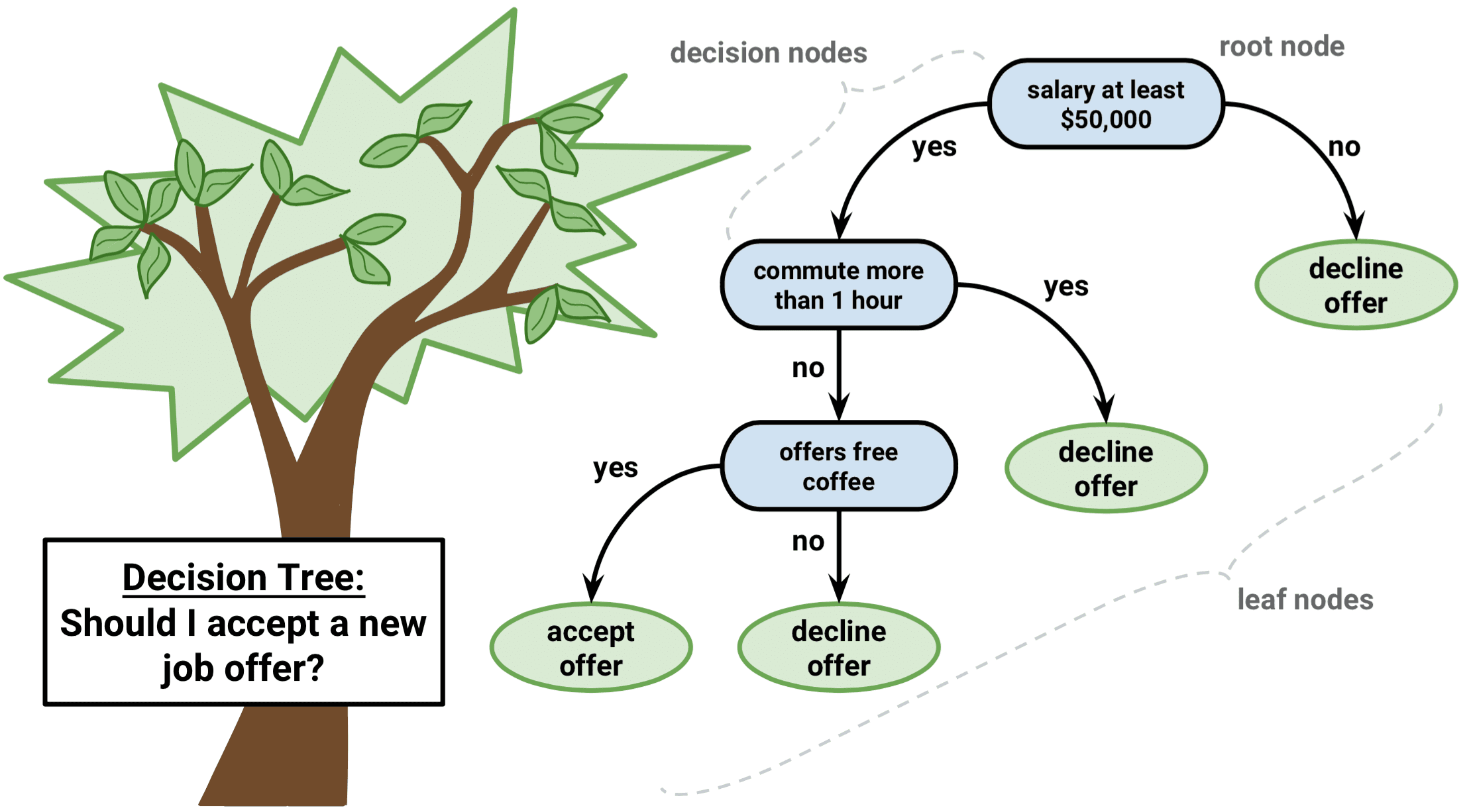
| Decision trees start with a single node, known as the root, which represents the entire dataset. The root node is then split into child nodes based on the values of a selected feature. The splitting process continues recursively until a stopping criterion is met. | ||
| 2 | ||
| Benefits of Decision Tree Classification Algorithm | ||
|---|---|---|
| Decision trees are easy to understand and interpret, making them suitable for explaining the reasoning behind decisions. They can handle both numerical and categorical data, making them versatile for various types of datasets. Decision trees can handle missing values and outliers effectively, reducing the need for data preprocessing. | ||
| 3 | ||
| Limitations of Decision Tree Classification Algorithm | ||
|---|---|---|
| Decision trees tend to overfit the training data, leading to poor generalization on unseen data. They are sensitive to small changes in data, which can result in different tree structures. Decision trees can create biased models if the training data is imbalanced. | ||
| 4 | ||
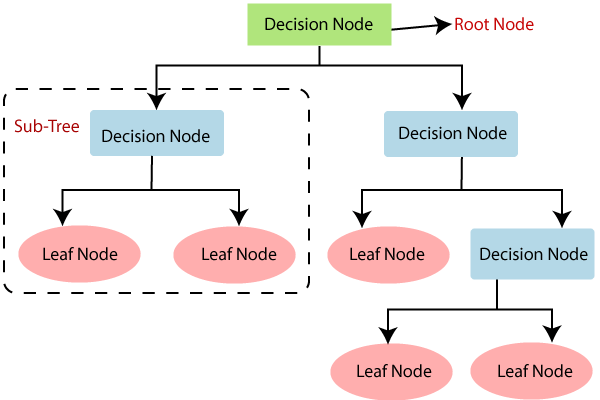
| Popular Decision Tree Algorithms | ||
|---|---|---|
| ID3 (Iterative Dichotomiser 3) is one of the earliest and simplest decision tree algorithms. C4.5 is an extension of ID3 and can handle both discrete and continuous attributes. CART (Classification and Regression Trees) is a versatile algorithm that can be used for both classification and regression tasks. | ||
| 5 | ||
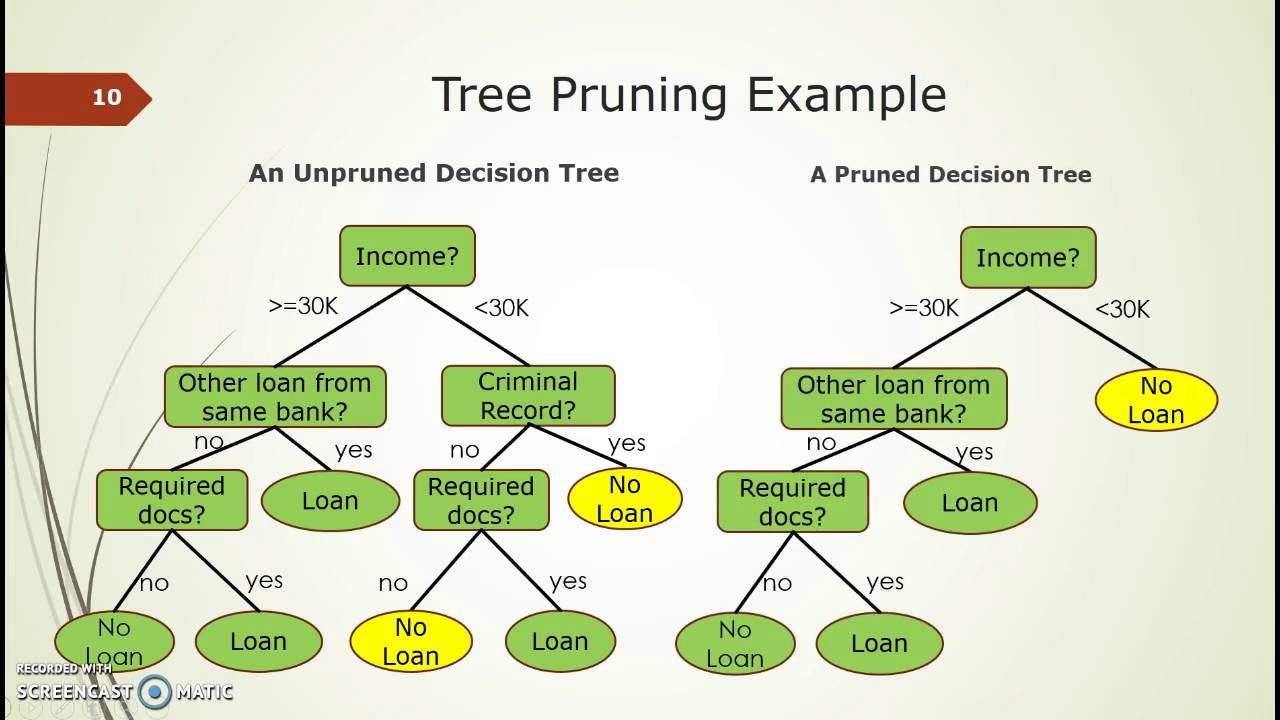
| Pruning in Decision Trees | ||
|---|---|---|
| Pruning is a technique used to reduce overfitting in decision trees. It involves removing unnecessary branches and nodes from the tree. Pruning can be performed using pre-pruning (early stopping criteria) or post-pruning (removing nodes after the tree is built). | ||
| 6 | ||
| Handling Missing Values in Decision Trees | ||
|---|---|---|
| Decision trees can handle missing values by assigning them to the most common class or by creating surrogate splits. Surrogate splits are alternative splits used when the selected feature has missing values. Missing values can also be imputed using techniques like mean imputation or regression imputation. | ||
| 7 | ||

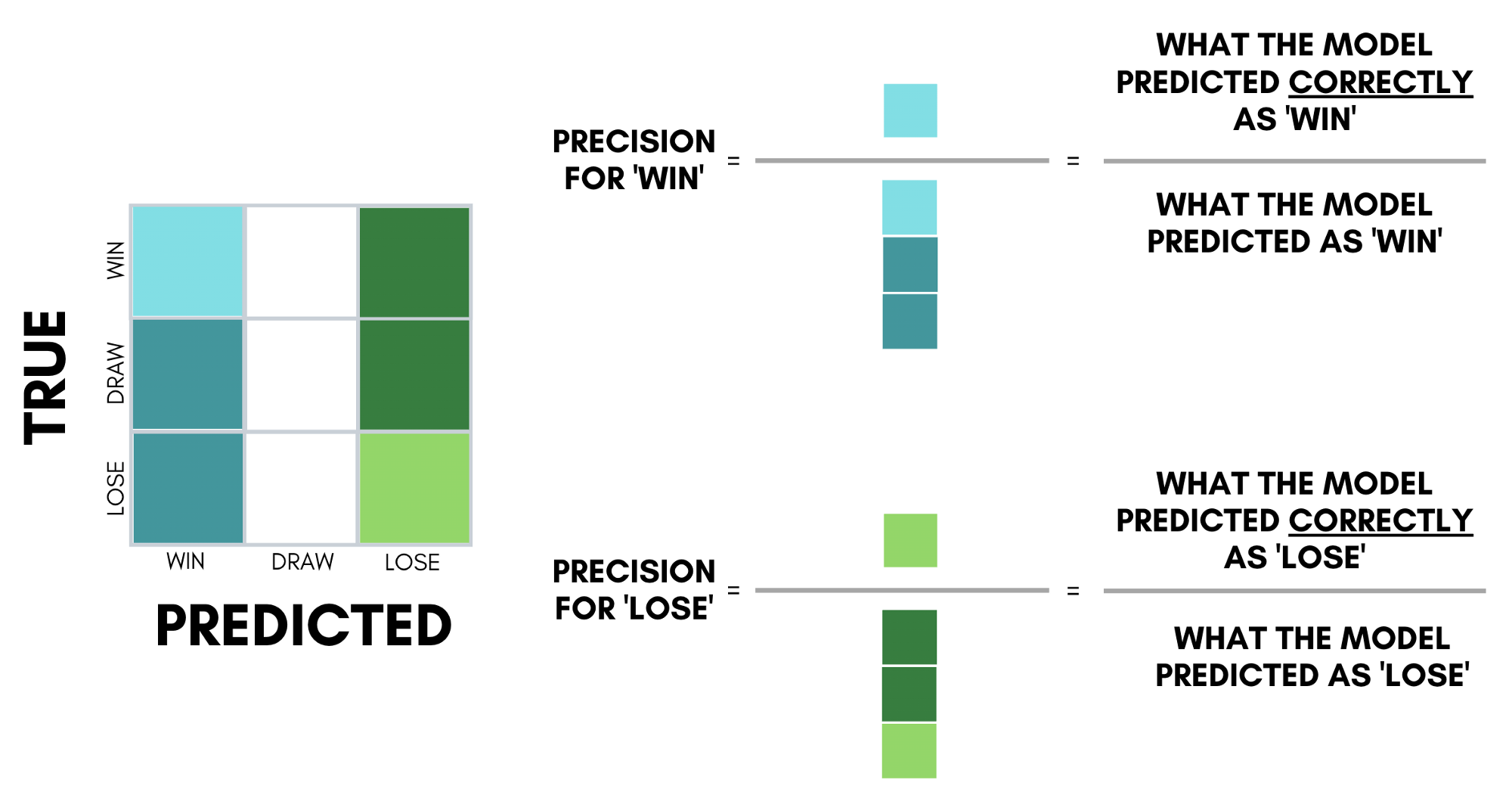
| Evaluating Decision Tree Models | ||
|---|---|---|
| Common evaluation metrics for decision tree models include accuracy, precision, recall, and F1 score. Cross-validation is often used to assess the model's generalization performance. Decision trees can also be visualized to gain insights into the decision-making process. | ||
| 8 | ||
| Ensemble Methods with Decision Trees | ||
|---|---|---|
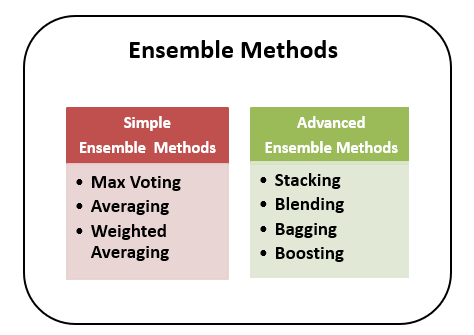
| Ensemble methods combine multiple decision trees to improve the overall performance. Random Forest is an ensemble method that creates a collection of decision trees and combines their predictions. Gradient Boosting is another popular ensemble method that builds decision trees sequentially, focusing on the errors of previous trees. | ||
| 9 | ||
| Conclusion | ||
|---|---|---|
| Decision tree classification is a powerful algorithm for solving classification problems. It offers interpretability, versatility, and the ability to handle various data types. By understanding its limitations and leveraging techniques like pruning and ensemble methods, decision trees can be further improved. | ||
| 10 | ||